- sort
- search
-
On-site personalization
Make your customers feel like your brand exactly knows what they want by adjusting the content elements and styles to their individual visitor preferences.
-
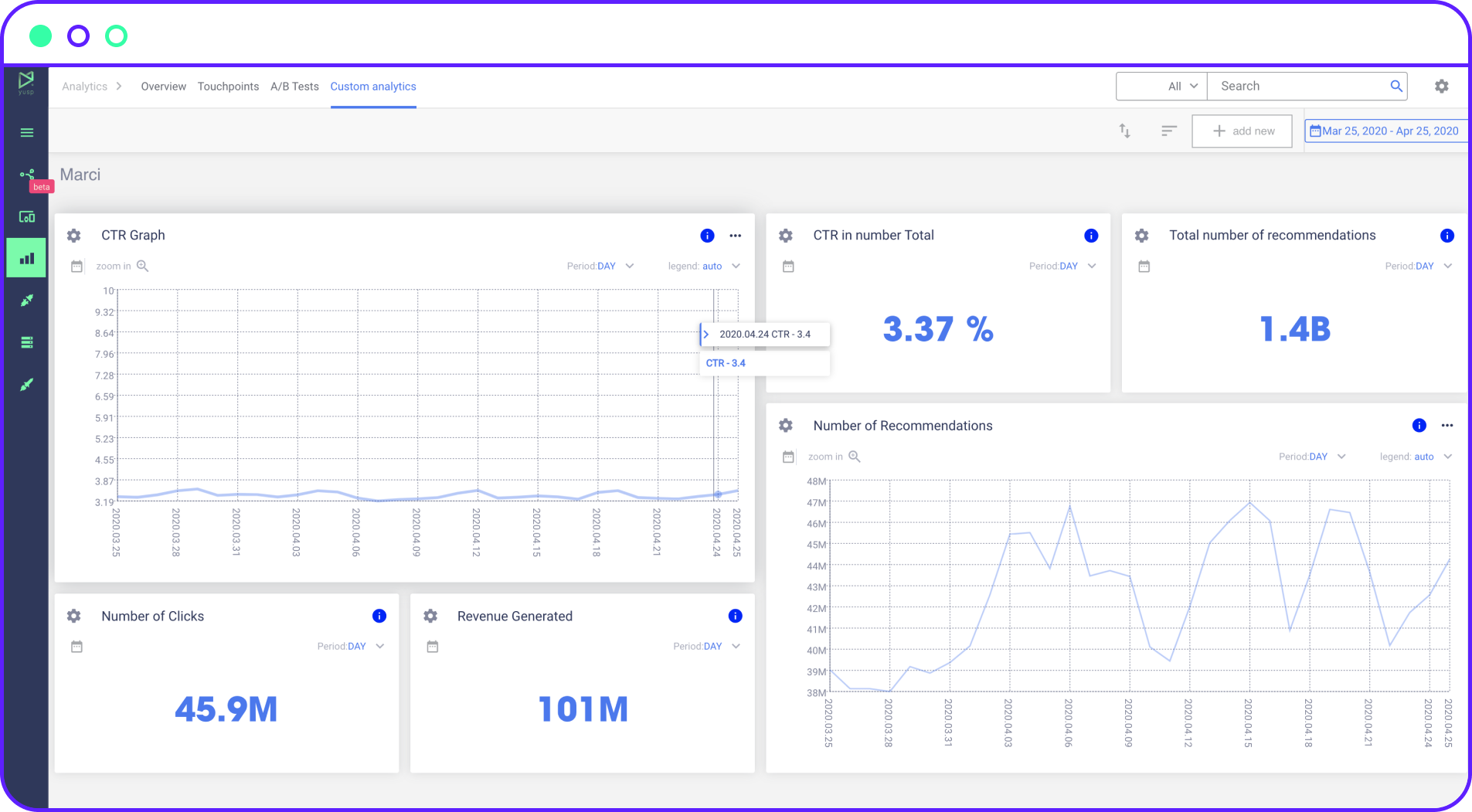
Recommendations
Inspire further shopping by displaying adaptive recommendations across the complete buying journey.
-
Marketing Channels
Use Yusp’s centralized engine to extend the customer journey from your site to your marketing channels by delivering personalized interactions to your customers in real-time.
-
Personalized Search
Better search engines lead to better results. Create a smooth product discovery experience on your site with Yusp's personalized search solutions.
-
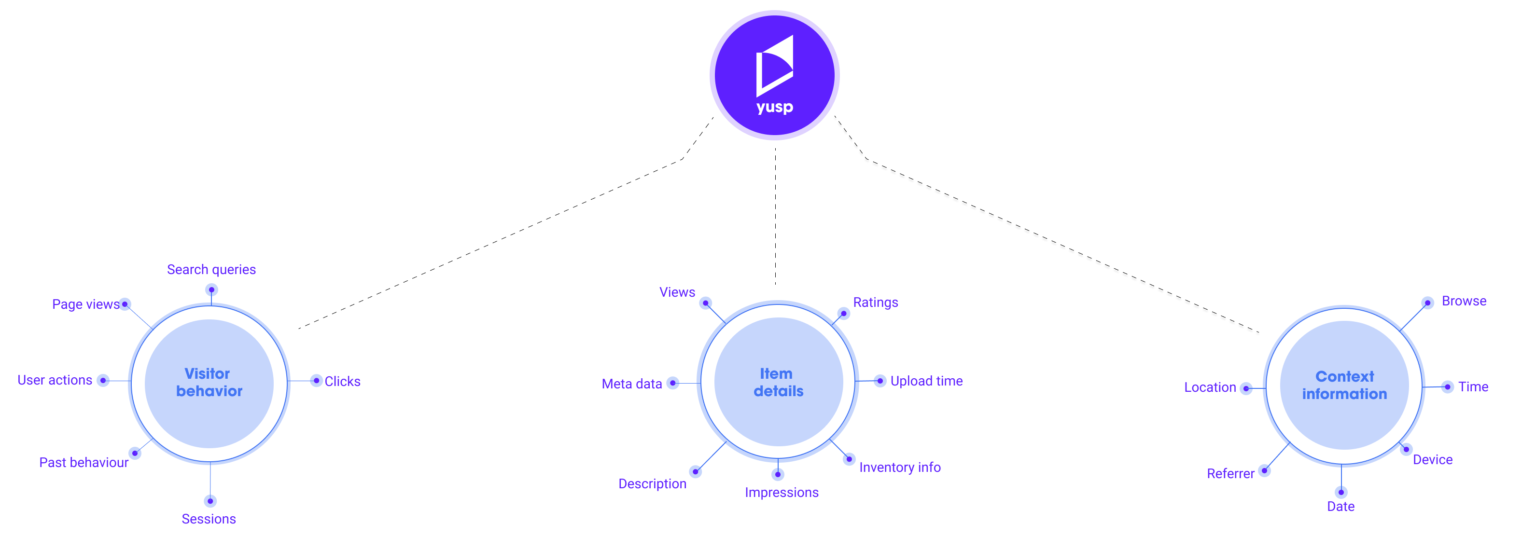
Why Yusp?
Performance and scalability to boost your business results at any scale
-
Blog posts
Check out insights, stories and thoughts on the latest in personalization, marketing and CX strategies.
-
Case studies
Get inspired through the personalization success stories of our clients and learn best practices from big brands.
-
Publications
Read the scientific publications of our data scientists on machine learning, deep learning, and more!
-
Knowledge base
Learn about personalization basics, paybooks, and strategies from our experts!